[튜토리얼] AI 에이전트의 성패를 가르는 ‘진짜’ 지식 기반 구축법, 이렇게 쉽고 정밀할 수가!
AI 에이전트의 성패를 가르는 ‘진짜’ 지식 기반 구축법, 이렇게 쉽고 정밀할 수가!
AI 에이전트를 만들 때 가장 중요한 건 ‘좋은 지식 기반’을 갖추는 것입니다. 이 영상에서는 Pinecone과 NADN을 활용해 벡터 데이터베이스에 메타데이터 임베딩과 텍스트 분할을 어떻게 적용하는지 쉽게 설명해 줍니다. 1) Pinecone 설정 2) 임베딩 생성 3) 텍스트 분할 4) 데이터 로드 5) 테스트 문서 활용 순서로 진행하며, 서버리스 환경에서 빠르고 저렴하게 구축하는 방법도 알려줍니다. AI 에이전트의 정확한 답변을 위해 꼭 필요한 기본 원리와 실습 예제를 친절하게 다뤄 초보자도 따라 하기 좋습니다. AI 지식 기반 구축에 관심 있다면 꼭 참고해 보세요!
[영상 정보]
- 영상 제목: Vector Database Optimization with n8n: Metadata, Text Splitting, & Embeddings
- 채널명: Nate Herk | AI Automation
- 업로드 날짜: 2024-12-04
- 영상 길이: 18:51
[영상에서 사용한 서비스]
- - Skool : https://www.skool.com/ — 커뮤니티 플랫폼, AI 자동화 관련 워크플로우 및 교육 제공
- - n8n : https://n8n.io/ — 노코드 워크플로우 자동화 도구
- - TrueHorizon : https://truehorizon.ai/ — AI 에이전트 비즈니스 도입 상담 서비스
- - Pinecone : https://www.pinecone.io/ — 벡터 데이터베이스 서비스, 임베딩 및 검색 기능 제공
- - YouTube : https://www.youtube.com/ — 영상 플랫폼, 배경음악 출처
- - Razer Kiyo Pro : https://www.razer.com/webcam-cameras/razer-kiyo-pro — 웹캠 카메라
- - HyperX SoloCast : https://www.hyperxgaming.com/unitedstates/us/microphones/solocast-gaming-microphone — 마이크
- - Pinecone : https://www.pinecone.io — 벡터 데이터베이스 서비스로, AI 에이전트의 지식 기반 구축 및 벡터 임베딩 저장과 검색에 사용
[주요 내용]

AI 에이전트 구축의 핵심은 좋은 지식 기반을 만드는 것입니다. 1) 벡터 데이터베이스 활용 2) 메타데이터 임베딩 3) 텍스트 분할 이해 4) Pinecone 설정 순으로 따라가면 정확한 답변 제공이 훨씬 수월해집니다.
서버리스 환경에서 임베딩을 쉽고 빠르게 설정하는 방법을 단계별로 알려줍니다. 1) 서버리스 선택 2) 임베딩 구성 3) API 키 발급 4) Pine Cone 연결 5) 테스트 문서 준비까지 친절하게 설명해, 처음 시작하는 분들도 부담 없이 따라 할 수 있어요.
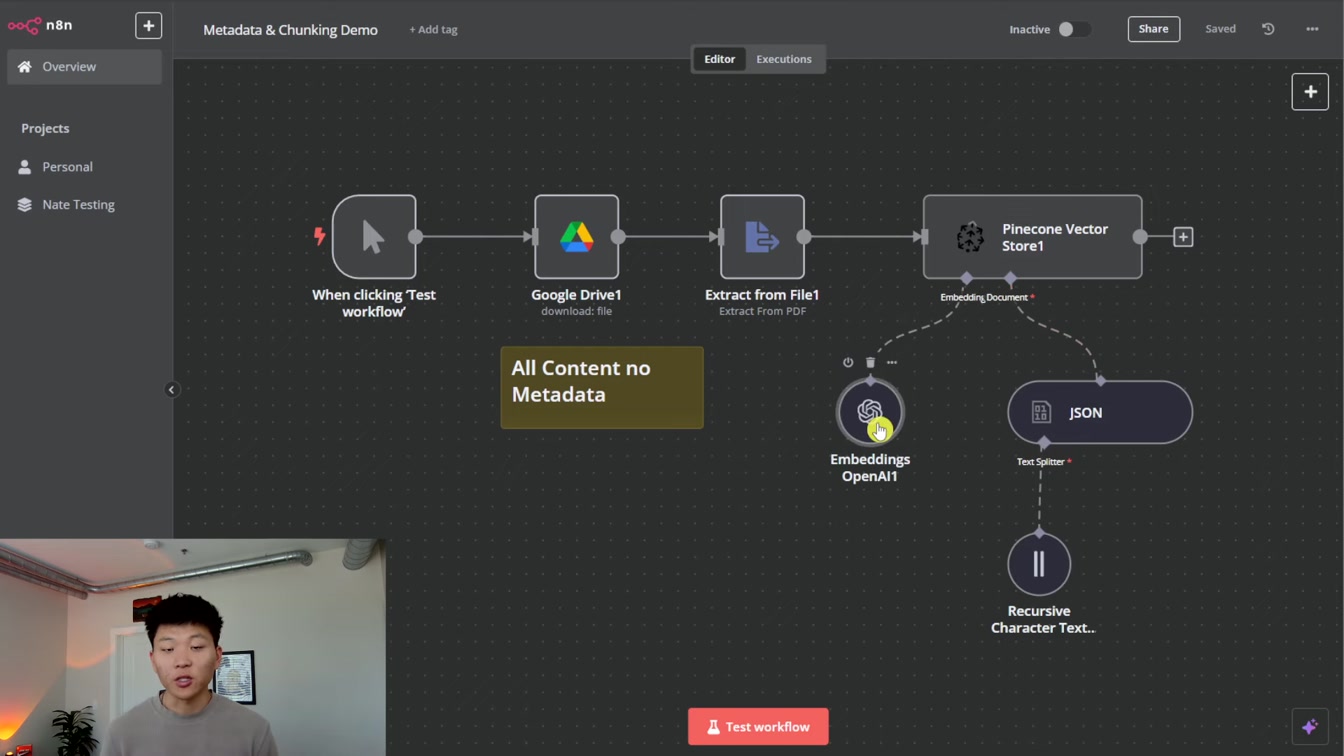
Pine Cone에 텍스트 임베딩을 올바르게 넣는 방법과 확인 절차를 쉽게 알려줍니다. 1) 임베딩 일치 여부 점검 2) JSON 또는 바이너리 데이터 로드 3) 재귀적 문자 분할 활용법까지 단계별로 친절하게 설명해 실무에 바로 적용할 수 있어요.
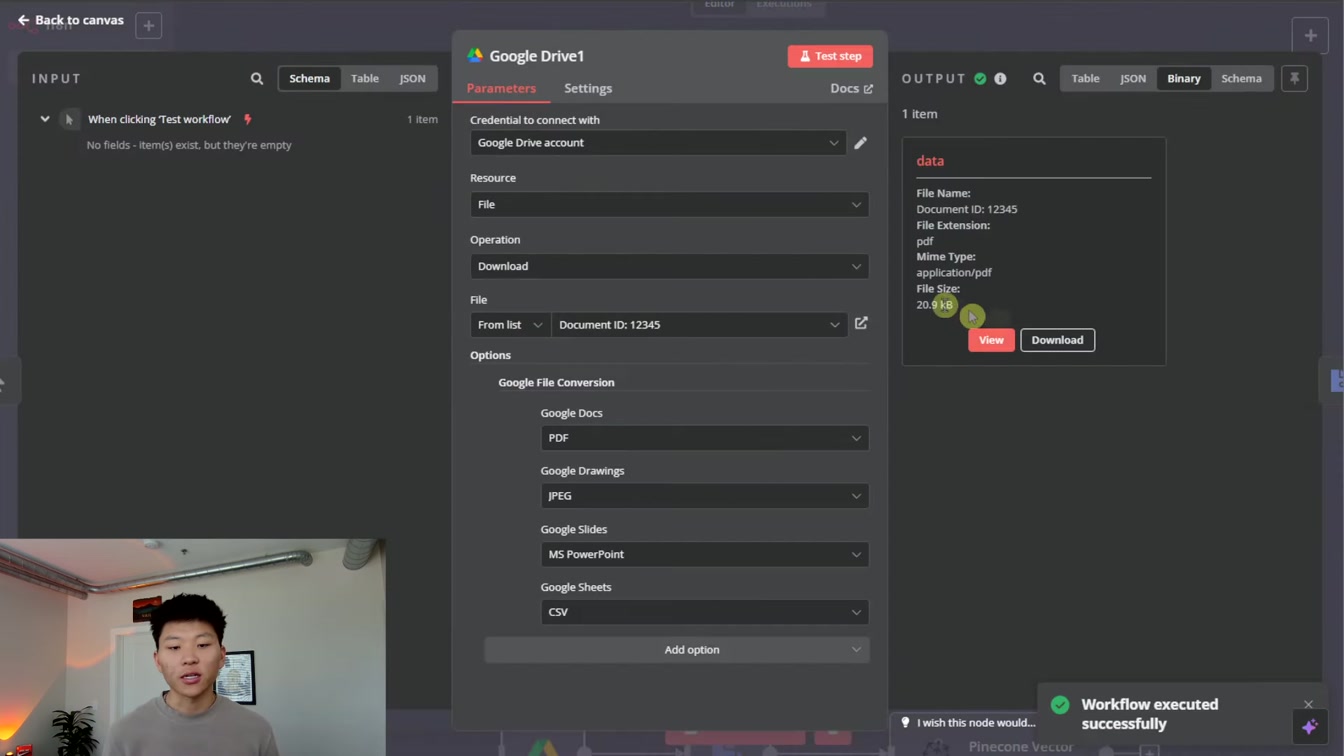
PDF에서 필요한 정보만 깔끔하게 추출하는 방법을 단계별로 알려줍니다. 1) PDF 파일 다운로드 2) 텍스트 추출 3) 불필요한 메타데이터 제거 4) 핵심 벡터 데이터만 선별 5) RAG 쿼리로 정확한 정보 검색까지 쉽게 따라 할 수 있어요.
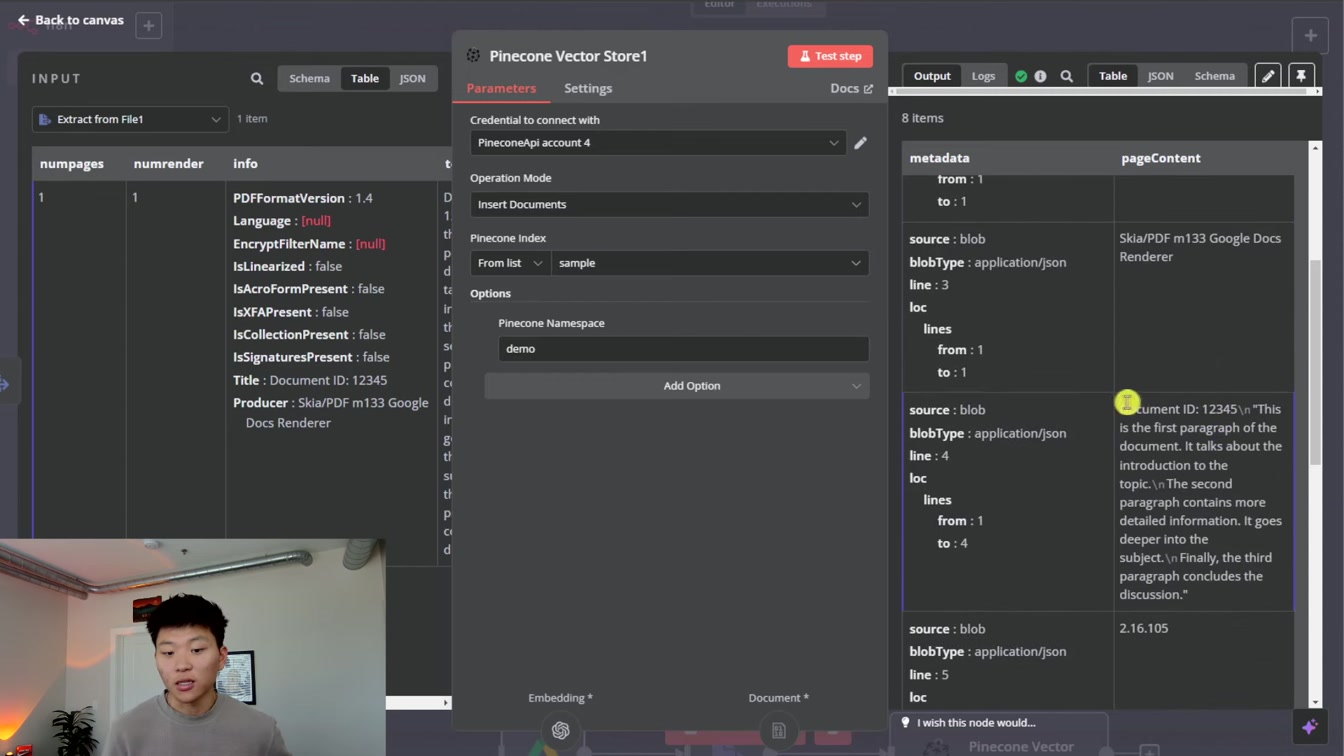
JSON 데이터를 재귀적으로 분할해 의미 있는 8개 실행 단위로 나누는 방법을 쉽게 설명합니다. 1) JSON 전체 가져오기 2) 재귀적 분할 3) 메타데이터 없는 콘텐츠 처리 4) 인덱스 새로 고침으로 벡터 입력 확인까지 단계별로 친절하게 안내해 줍니다.
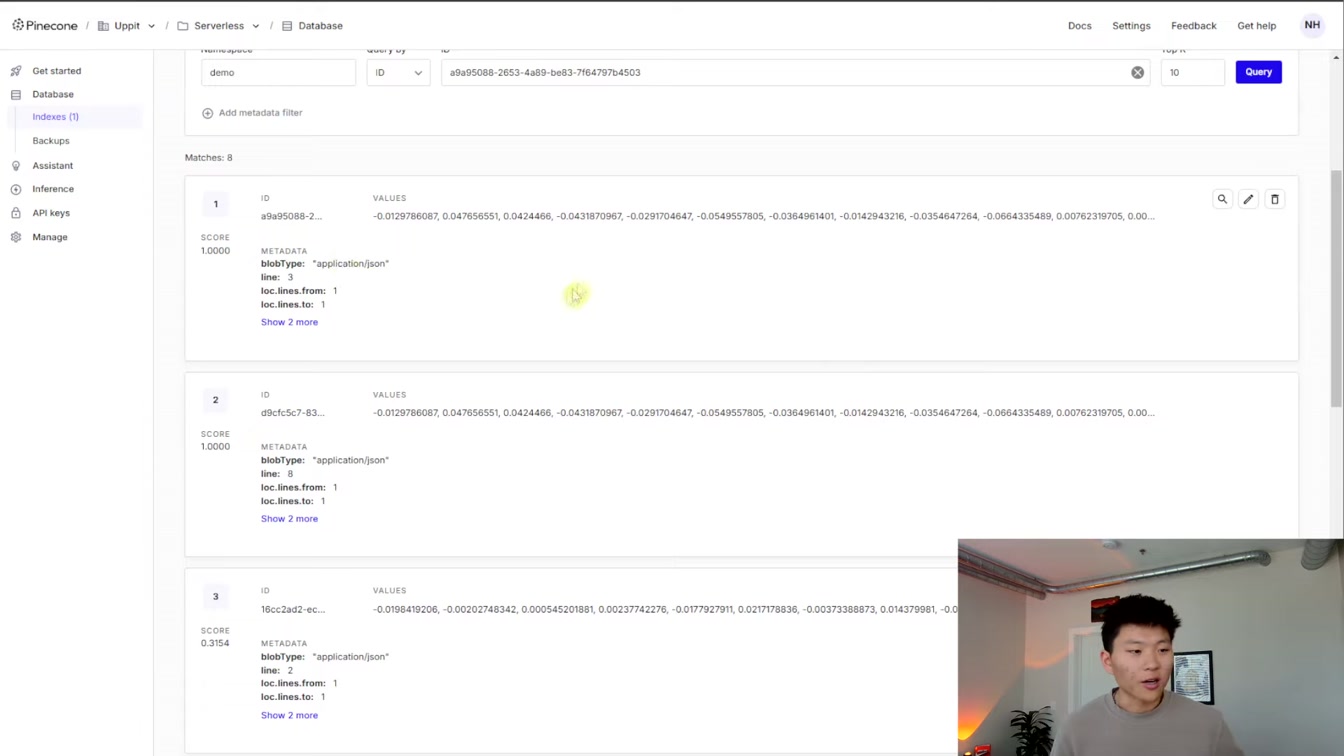
벡터 데이터에서 원하는 정보를 찾는 방법과 인덱스 관리법을 쉽게 알려줍니다. 1) 올바른 레코드 확인 2) 불필요한 인덱스 삭제 3) 예제 워크플로 다운로드까지 친절하게 안내해 실무에 바로 활용할 수 있어요.
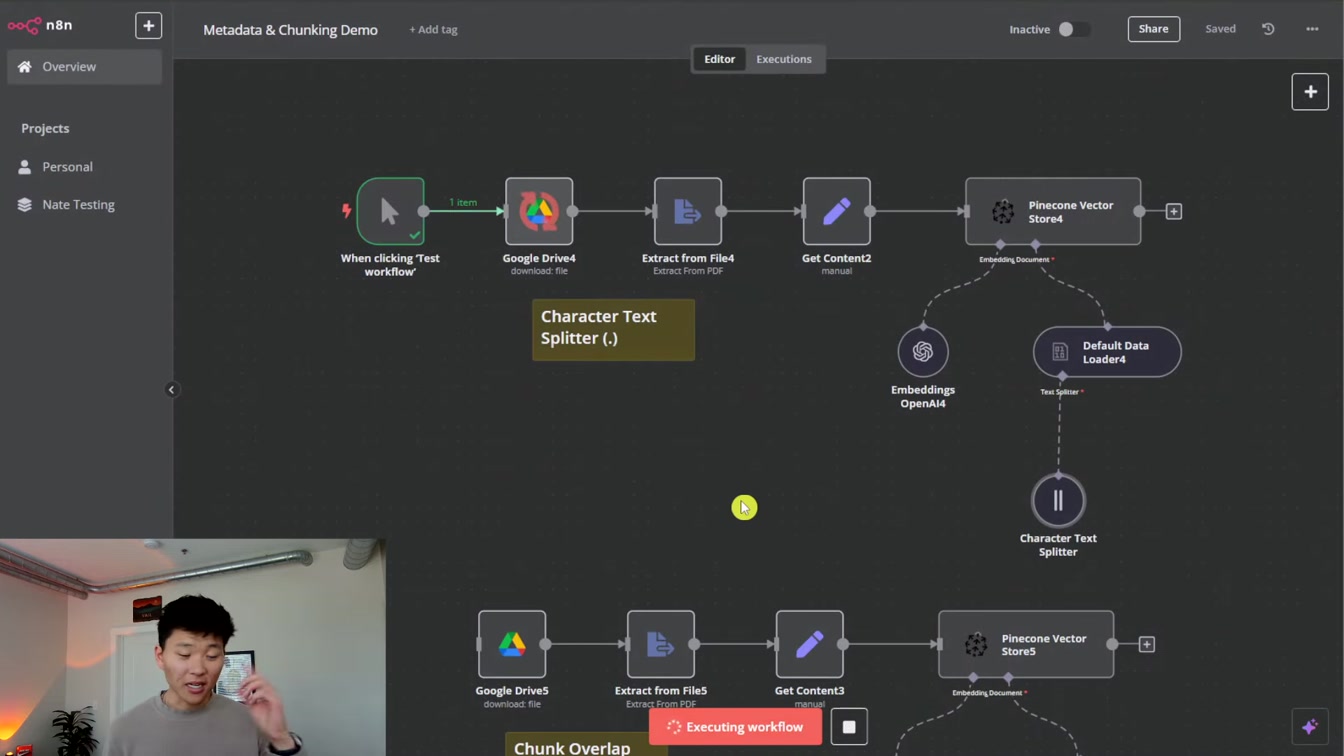
벡터 데이터베이스를 직접 파일에서 불러와 AI 자동화에 활용하는 방법을 쉽게 알려줍니다. 1) 파일에서 nend 인스턴스 생성 2) 벡터 데이터베이스 이해 3) 유료 커뮤니티 참여로 심화 학습까지, 실무에 꼭 필요한 단계별 팁을 친절하게 소개해요.
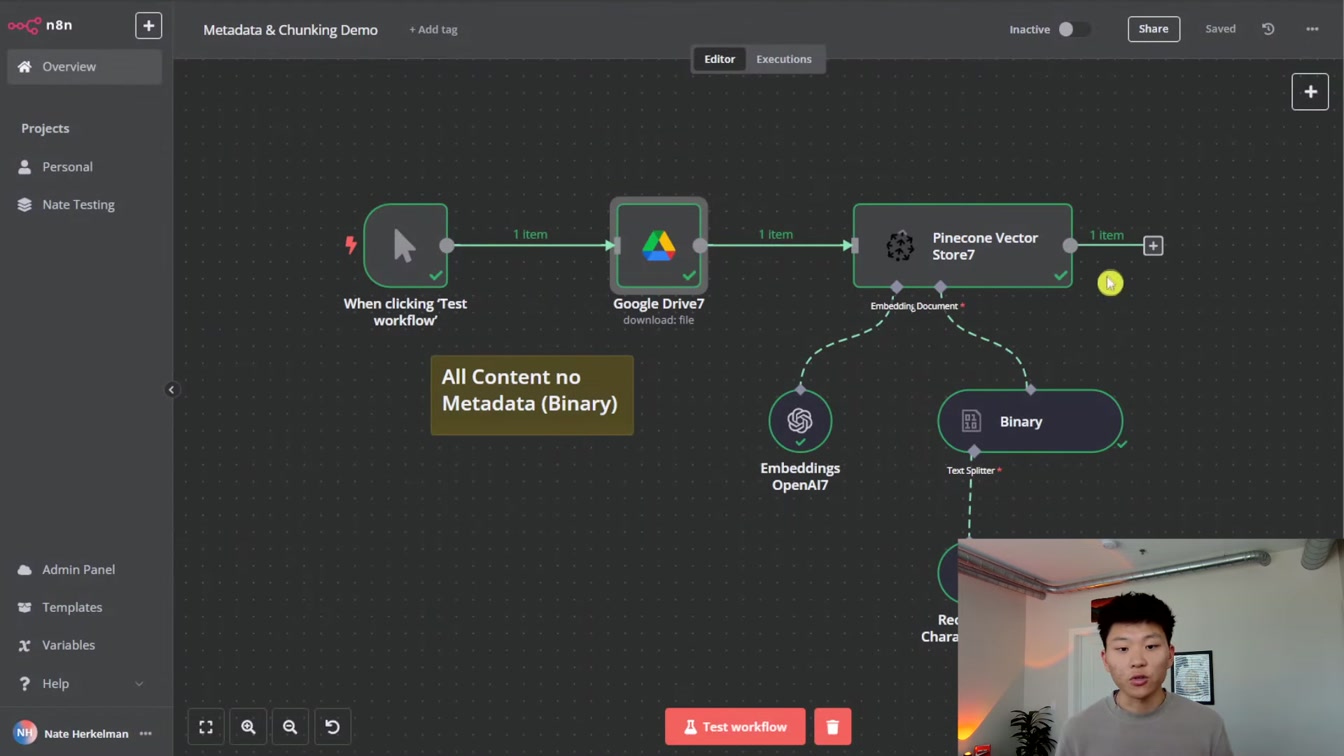
소나무 열매에서 이진 분할로 공백을 제거하고 실제 텍스트만 깔끔하게 추출하는 방법을 보여줍니다. 1) 바이너리 직접 로드 2) 재귀 임베드 생성 3) 메타데이터 포함 확인 4) 벡터 최적화로 검색 속도 유지까지 친절하게 설명해 줍니다.
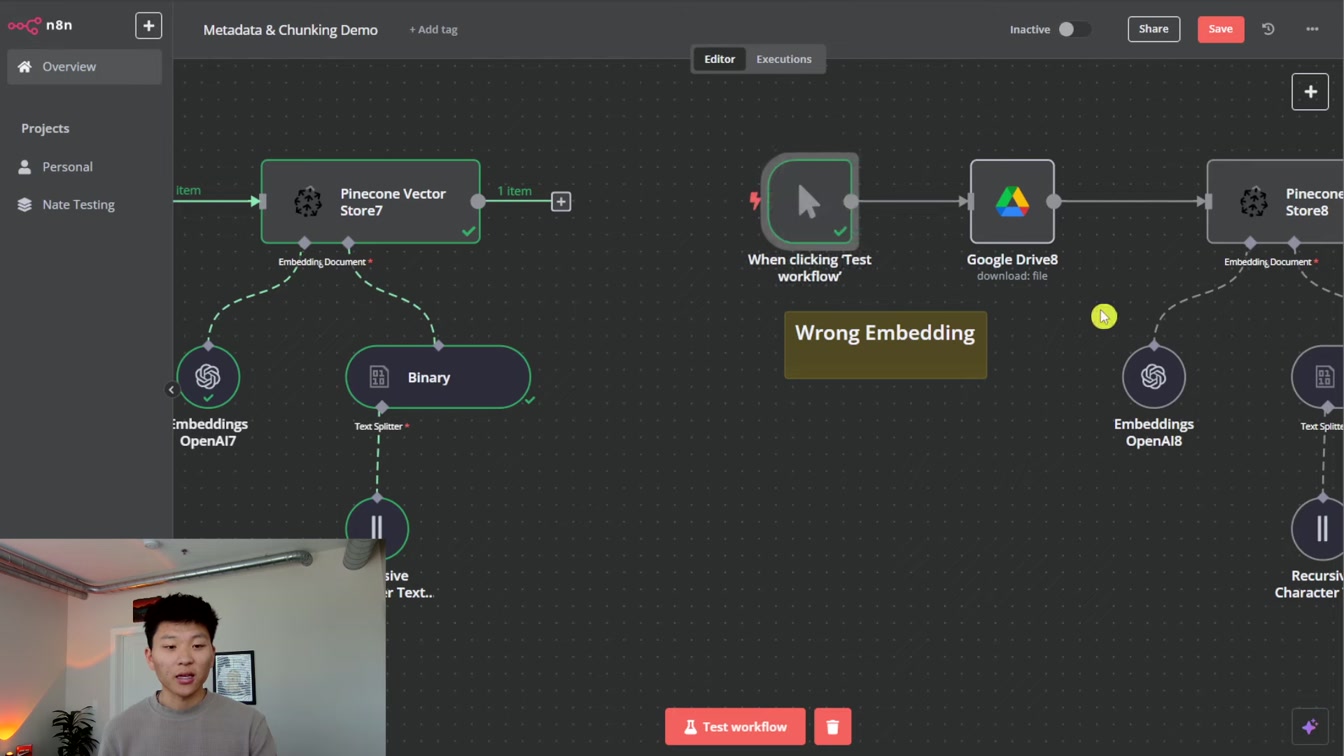
임베딩 차원과 값 크기가 맞지 않으면 임베드가 실패할 수 있어요. 1) 큰 값 대신 작은 값 사용 2) 차원 수 확인 3) 수치적 표현으로 변환해 관련 데이터 찾기 과정을 쉽게 이해할 수 있습니다.
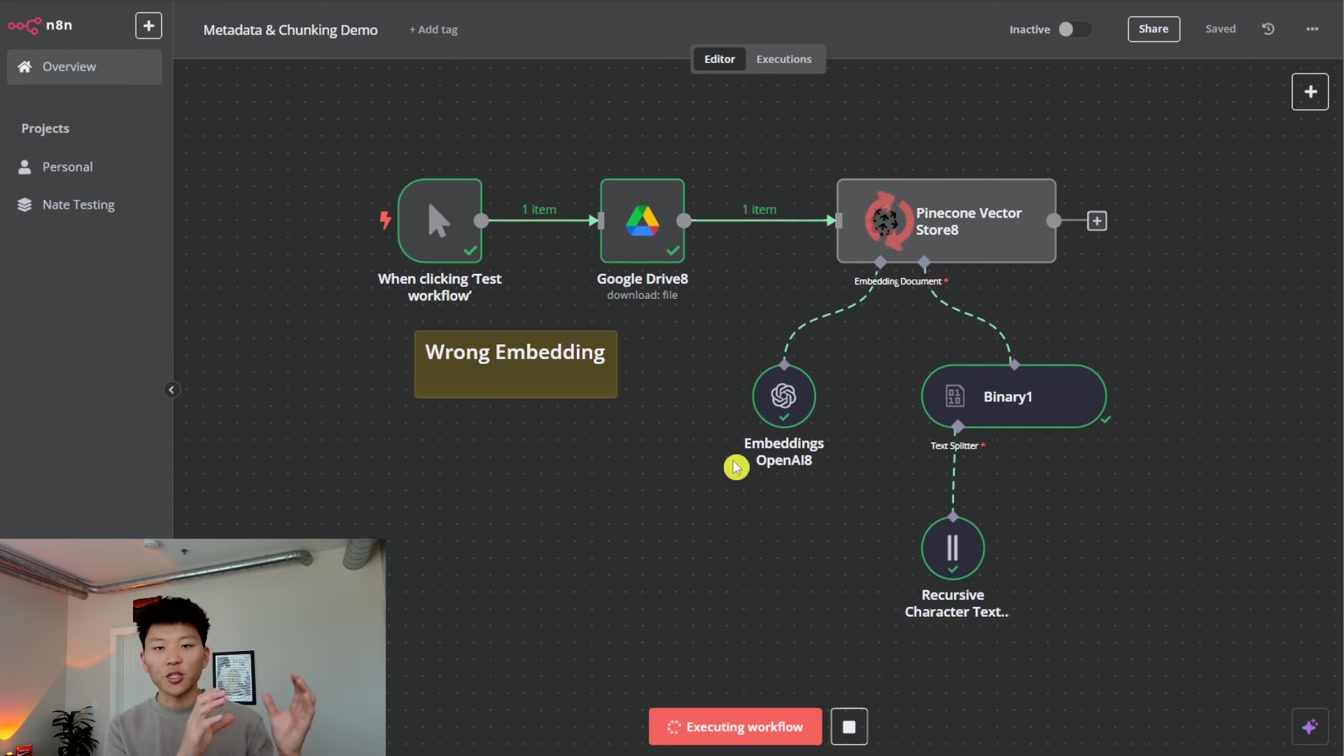
벡터 인덱스 정렬이 왜 중요한지 쉽게 알려줍니다. 1) 차원 불일치 문제 2) 무한 회전 오류 3) 메타데이터 활용법까지 차근차근 설명해 실무에 바로 적용할 수 있어요.
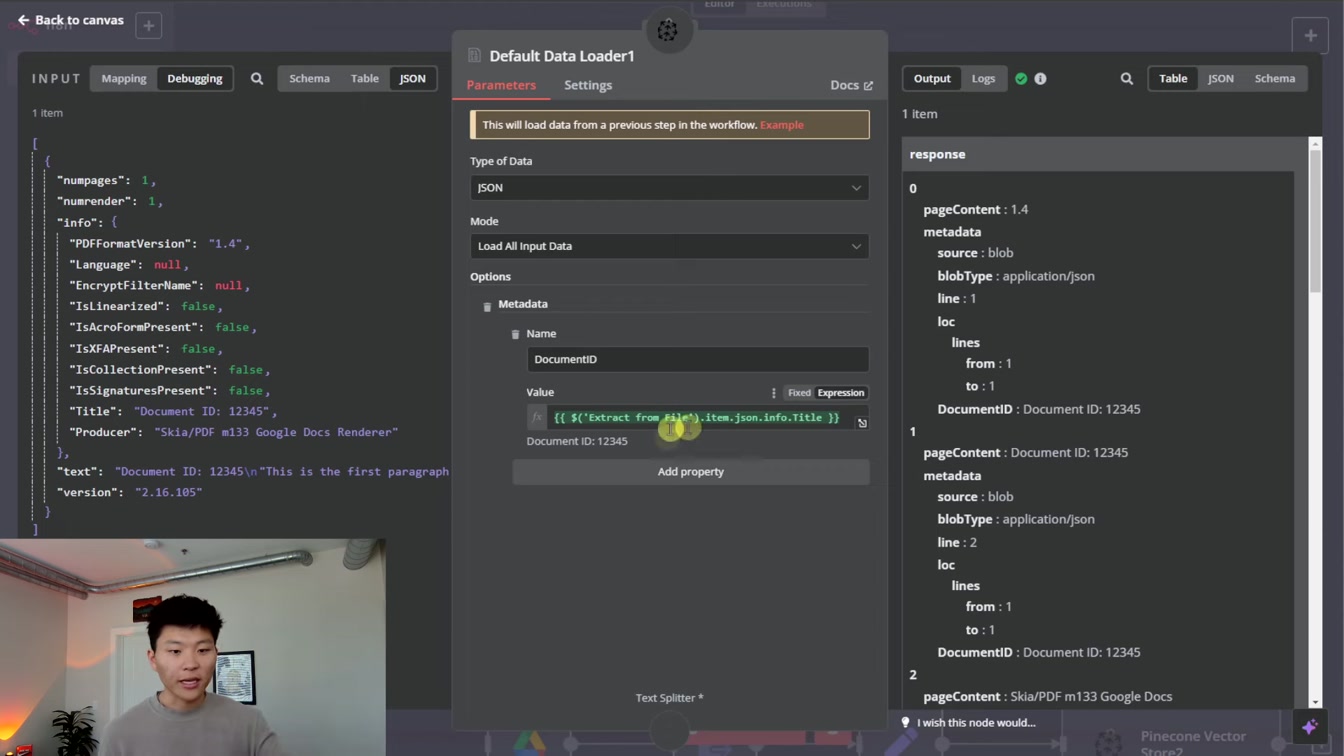
문서 ID와 메타데이터를 활용해 벡터 데이터를 효율적으로 관리하는 방법을 쉽게 알려줍니다. 1) 파일에서 문서 ID 추출 2) 벡터별 메타데이터 확인 3) 실제 텍스트 위치 파악 4) 불필요한 정보 삭제 5) JSON 형식으로 데이터 로드까지 단계별로 친절하게 설명해 이해하기 편해요.
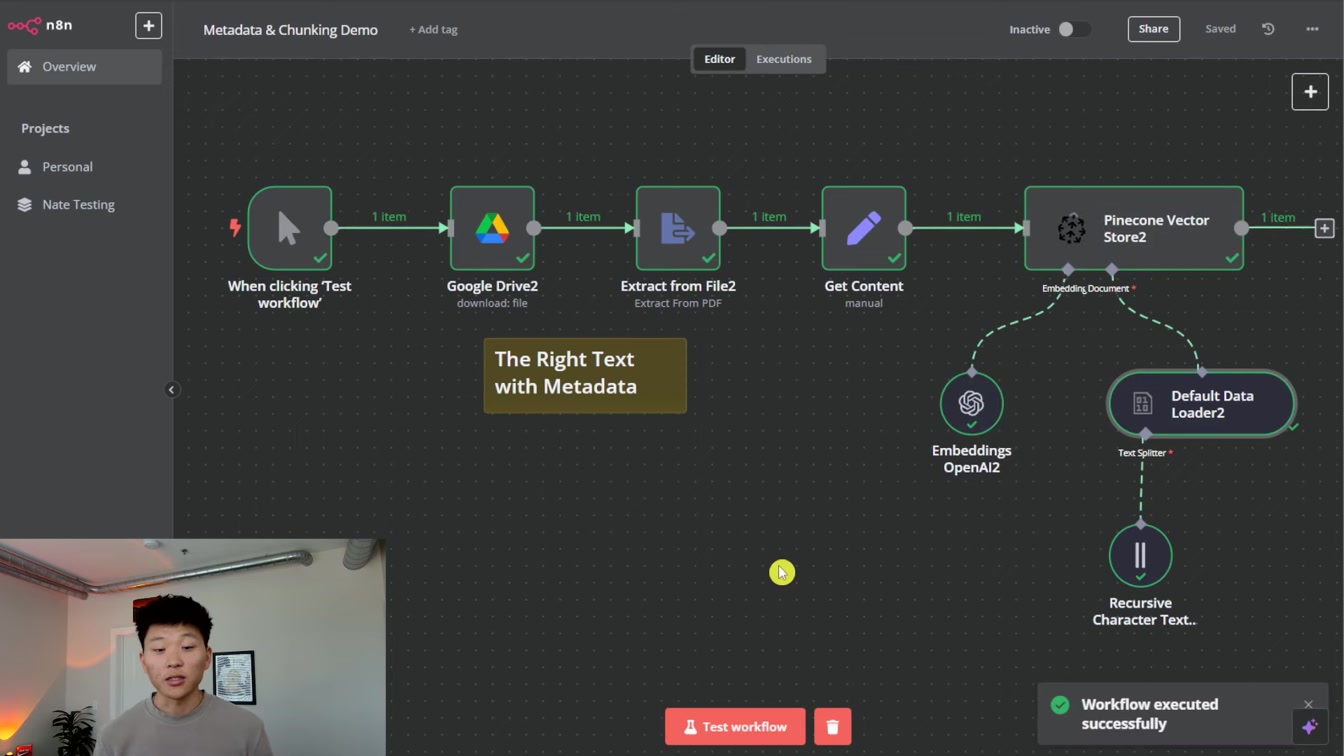
벡터 생성과 메타데이터 활용법을 쉽게 알려줍니다. 1) 벡터 만들기 2) 텍스트와 문서 ID 포함 3) 자동 새로고침 확인까지 친절하게 설명해, 데이터 관리에 도움됩니다.
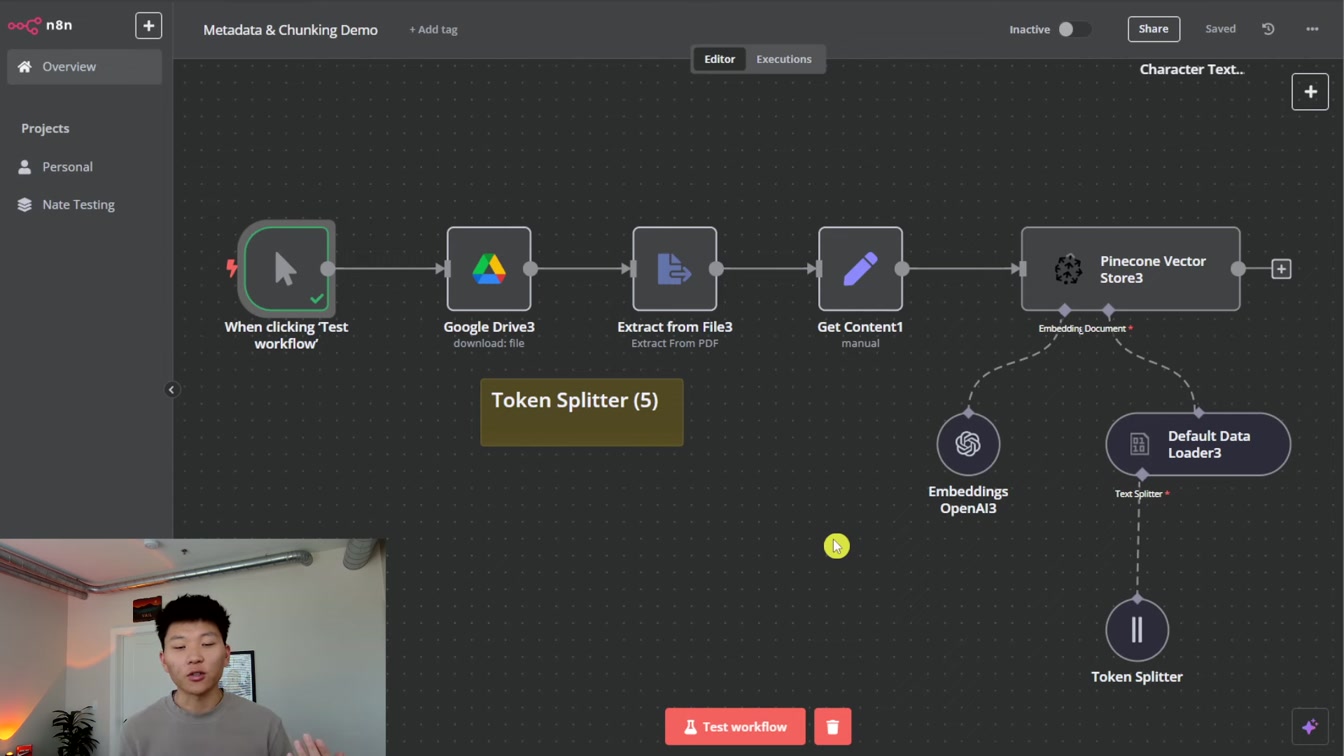
거대한 문서를 효율적으로 다루려면 1) 문맥 유지 2) 적절한 분할 3) 토큰 단위 청크 설정(예: 5개) 순서로 나누는 방법이 도움이 됩니다. 이렇게 하면 복잡한 내용도 깔끔하게 정리할 수 있어요.
소나무 열매 데이터에서 10개 항목을 라이브로 확인하는 방법과, 5개씩 겹치며 나누는 청크 처리 과정을 쉽게 따라할 수 있도록 단계별로 설명해 드려요. 새로 고침 팁도 함께 알려주니 데이터 관리에 도움이 될 거예요.
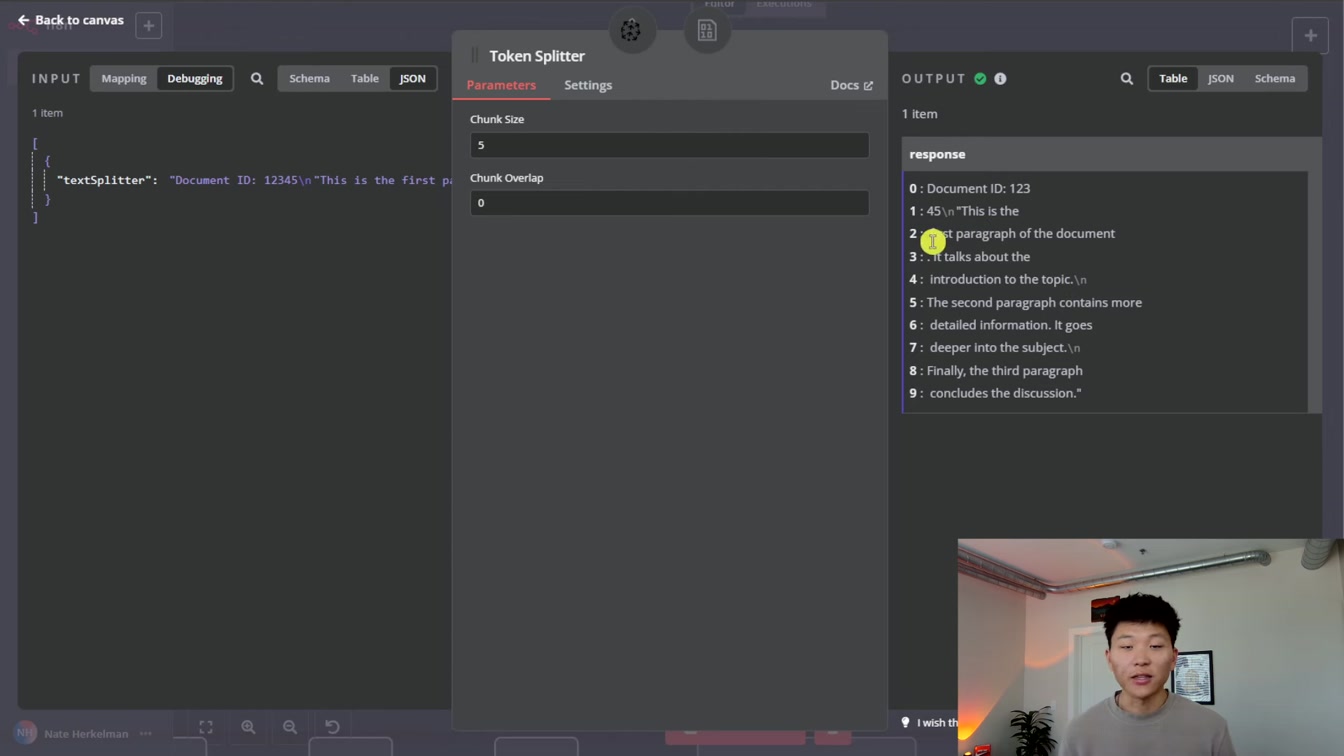
토큰 분할과 문자 텍스트 분할 방식을 쉽게 이해할 수 있어요. 1) 벡터 중복 제거 2) 재귀적 텍스트 분할 3) 청크 크기와 겹침 설정 순서로 설명해 주니, 텍스트 처리 과정이 한눈에 들어옵니다.
문장 단위로 데이터를 나누고 마침표 기준으로 청크를 구분하는 방법을 친절하게 설명합니다. 1) 문장 끝 마침표 확인 2) 청크 크기 50 도달 시 멈춤 3) 문맥 손실 없이 벡터 생성하는 실용적 팁을 배울 수 있어요.
문장을 중간에서 끊지 않고 완전하게 나누는 방법과, 재귀적 텍스트 분할 아이디어를 활용해 청크 겹침을 적용하는 과정을 쉽게 설명합니다. 1) 문장 단위 분할 2) 청크 크기 설정 3) 겹침 적용 순서로 이해할 수 있어 텍스트 처리에 도움됩니다.
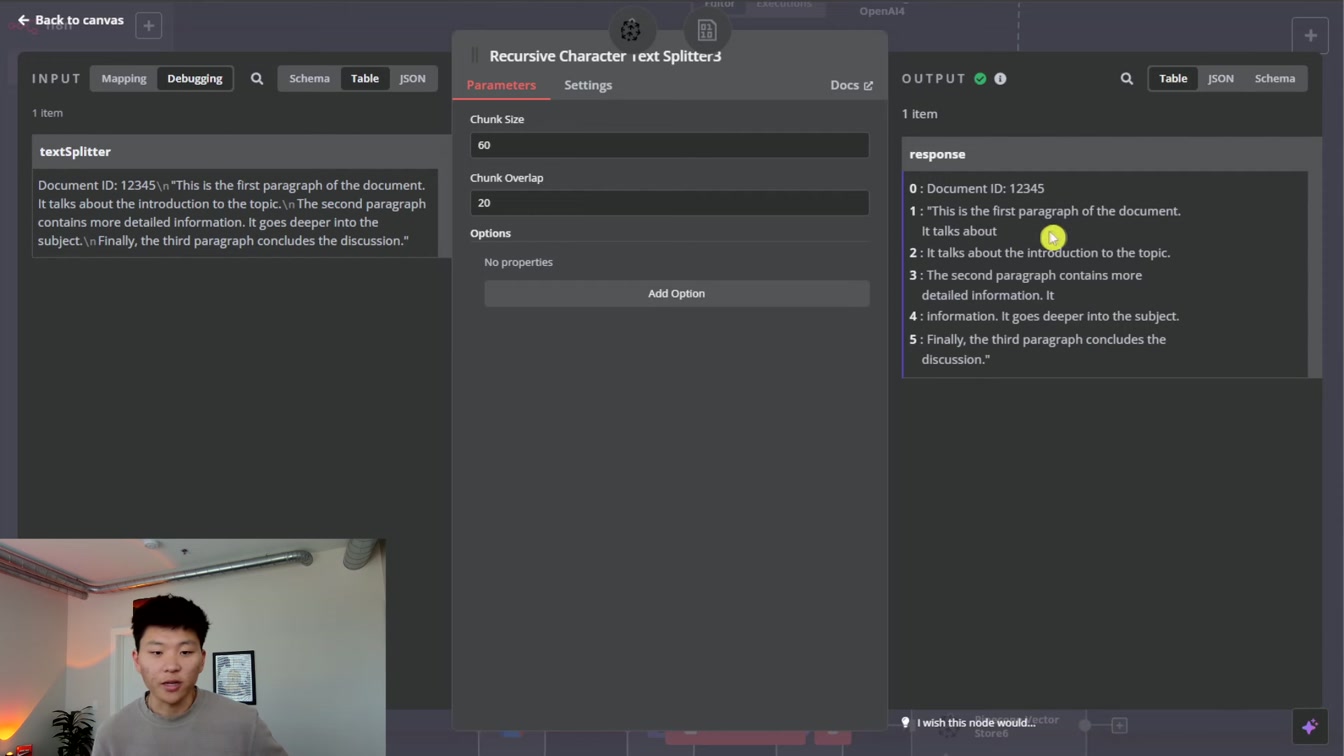
문서의 각 문단을 벡터로 나누어 정보 손실 없이 반복과 맥락을 유지하는 방법을 친절하게 설명합니다. 1) 문단별 벡터 생성 2) 중복과 겹침 최소화 3) 큰 청크 사용 시 정보 보존 4) 비용과 효율성 균형 맞추기 과정을 쉽게 이해할 수 있어요.
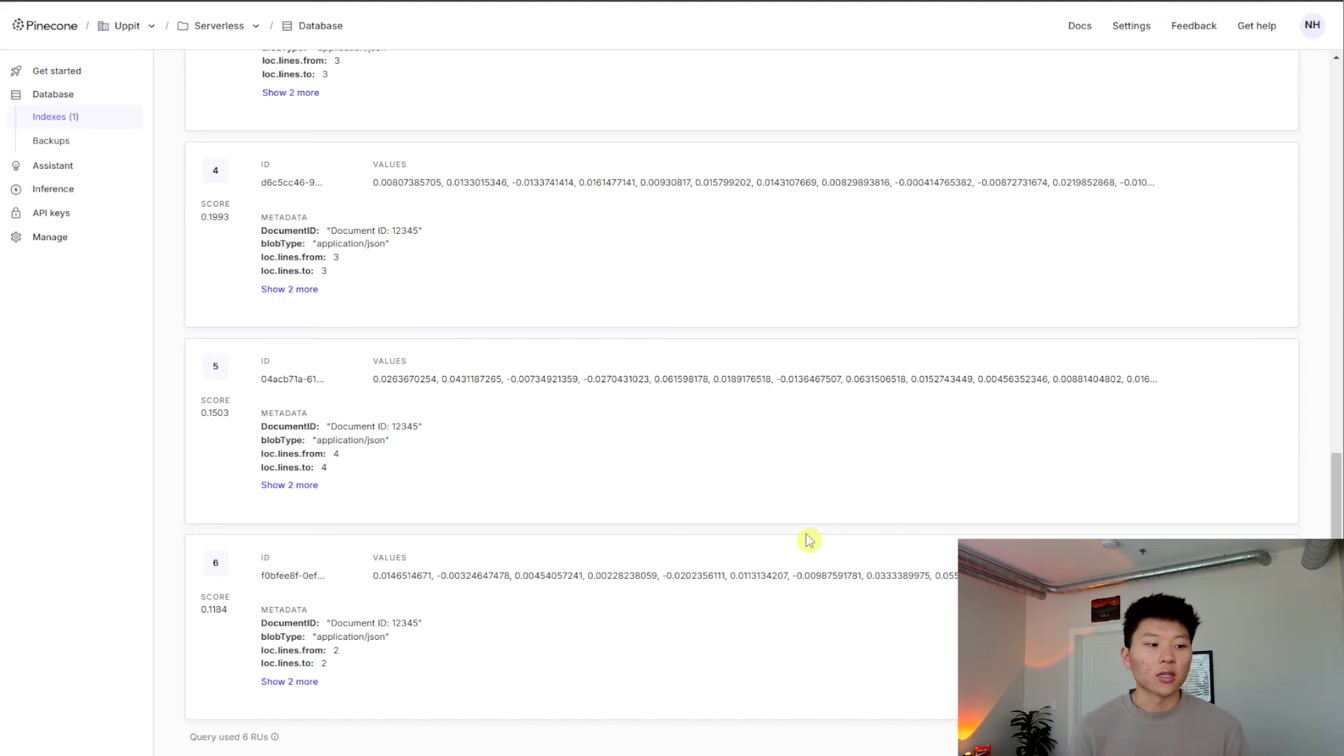
rag와 super base를 활용해 문서 정보를 쉽게 업데이트하는 방법을 단계별로 알려줍니다. 1) 기존 문서 삭제 2) 메타데이터 ID 확인 3) 새 문서로 새로 고침 4) 변경된 항목 반영까지 자연스럽게 처리하는 팁을 친절하게 소개해요.
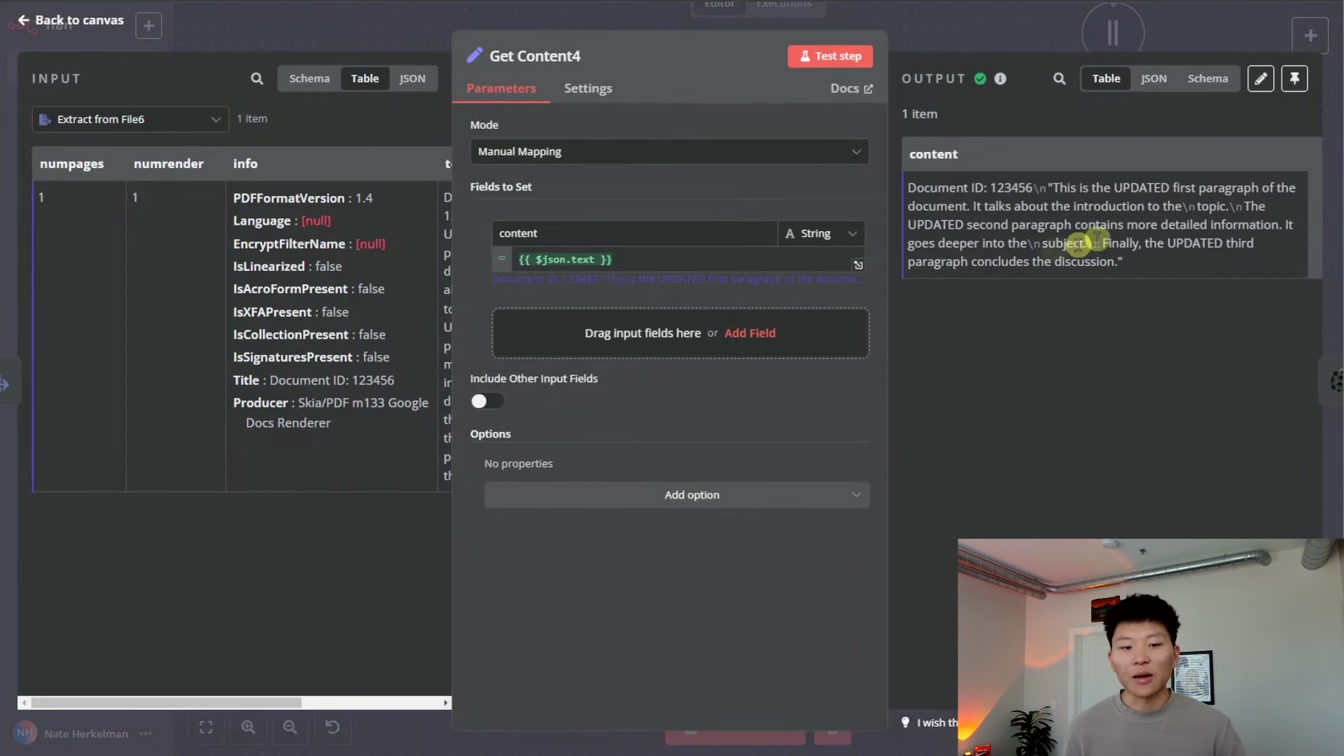
문서 업데이트 시 벡터 ID 관리가 중요하다는 점과, 솔방울(Pinecone)과 슈퍼베이스 차이를 이해하는 방법을 친절하게 알려줍니다. 1) 문서 ID 추가 2) 벡터 개수 확인 3) 동적 ID 처리 순서로 쉽게 따라할 수 있어요.
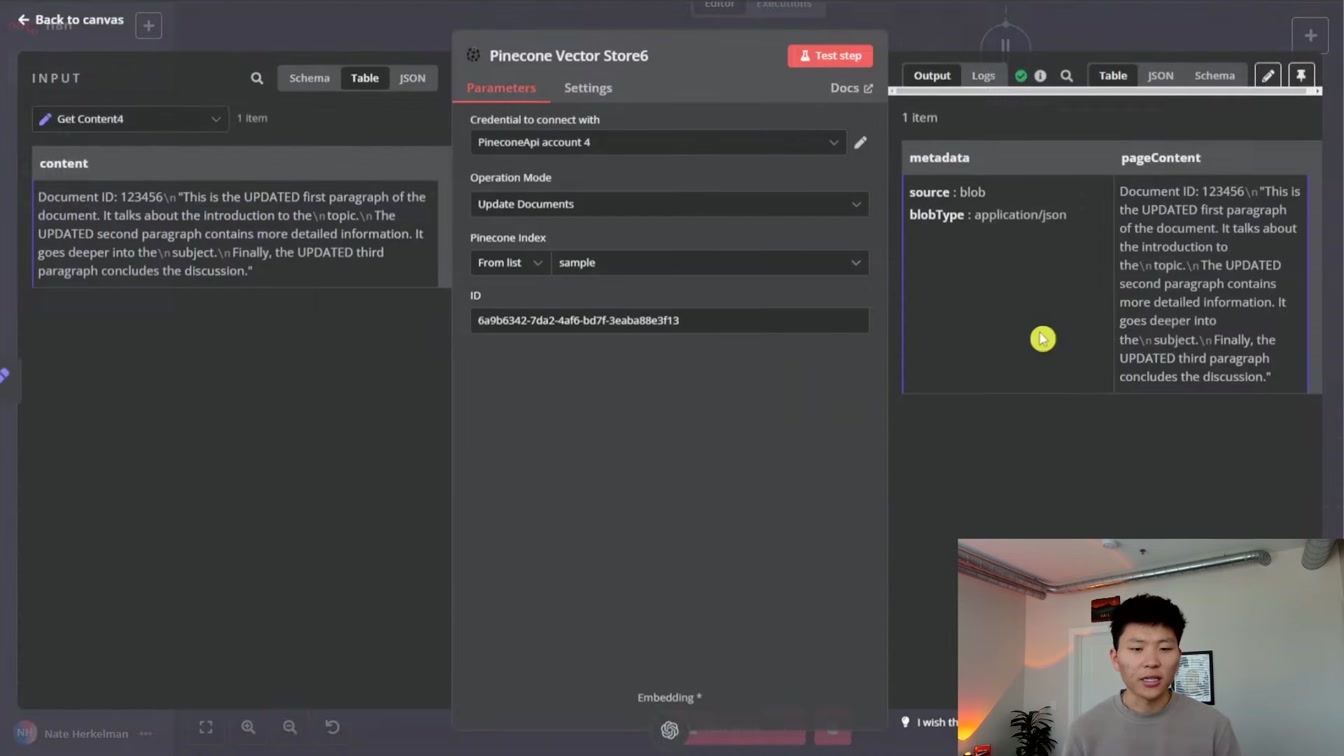
벡터 내장 방식으로 원하는 정보를 쉽게 얻는 과정을 보여줍니다. 분할기 없이도 문서 ID를 활용해 데이터를 찾는 방법과, 소나무 열매 예시로 벡터 업데이트 후 결과를 확인하는 단계가 자연스럽게 설명되어 있어요. AI 데이터 처리나 벡터 검색에 관심 있는 분께 추천합니다.
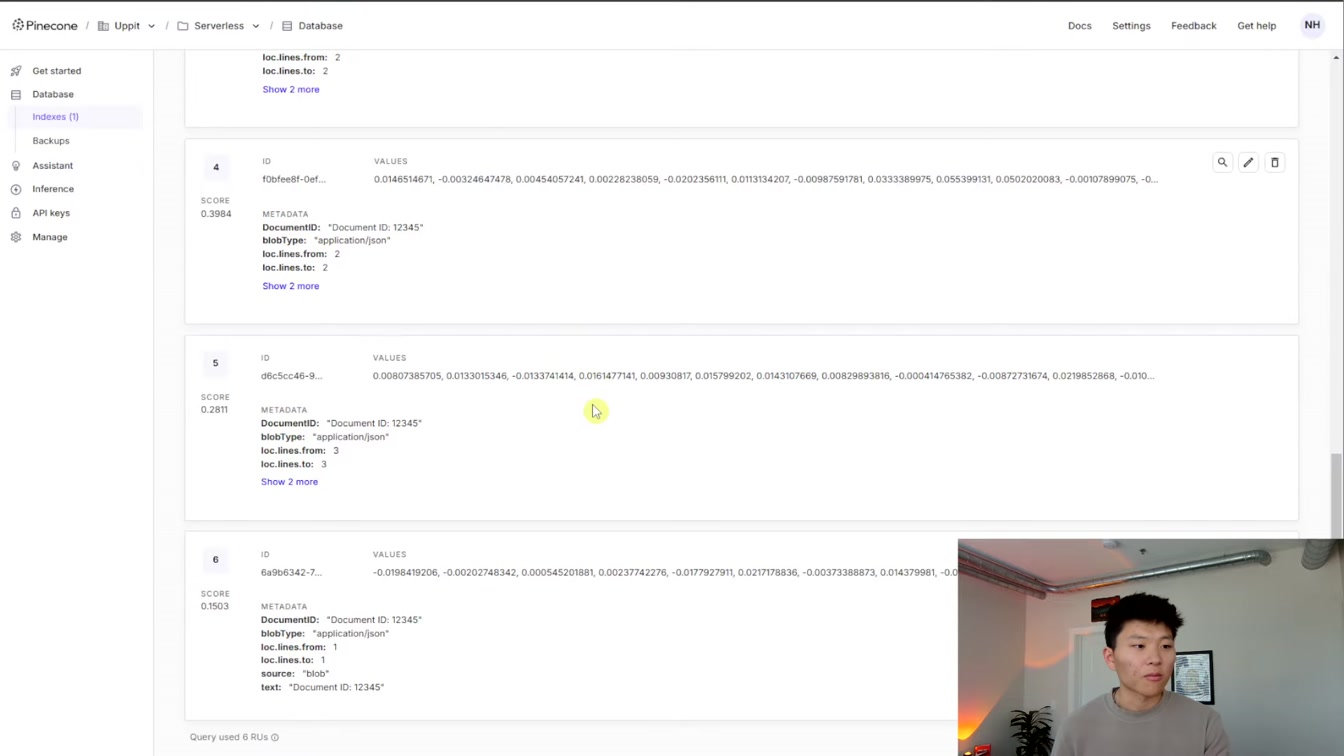
소나무 열매 데이터를 새로 고치며 10개 항목을 확인하는 과정과 업데이트된 정보를 찾는 방법을 친절하게 설명합니다. 1) 데이터 새로 고침 2) 항목 확인 3) 업데이트 여부 점검 4) 네임스페이스 활용법까지 실용적으로 알려줘 이해하기 쉽습니다.
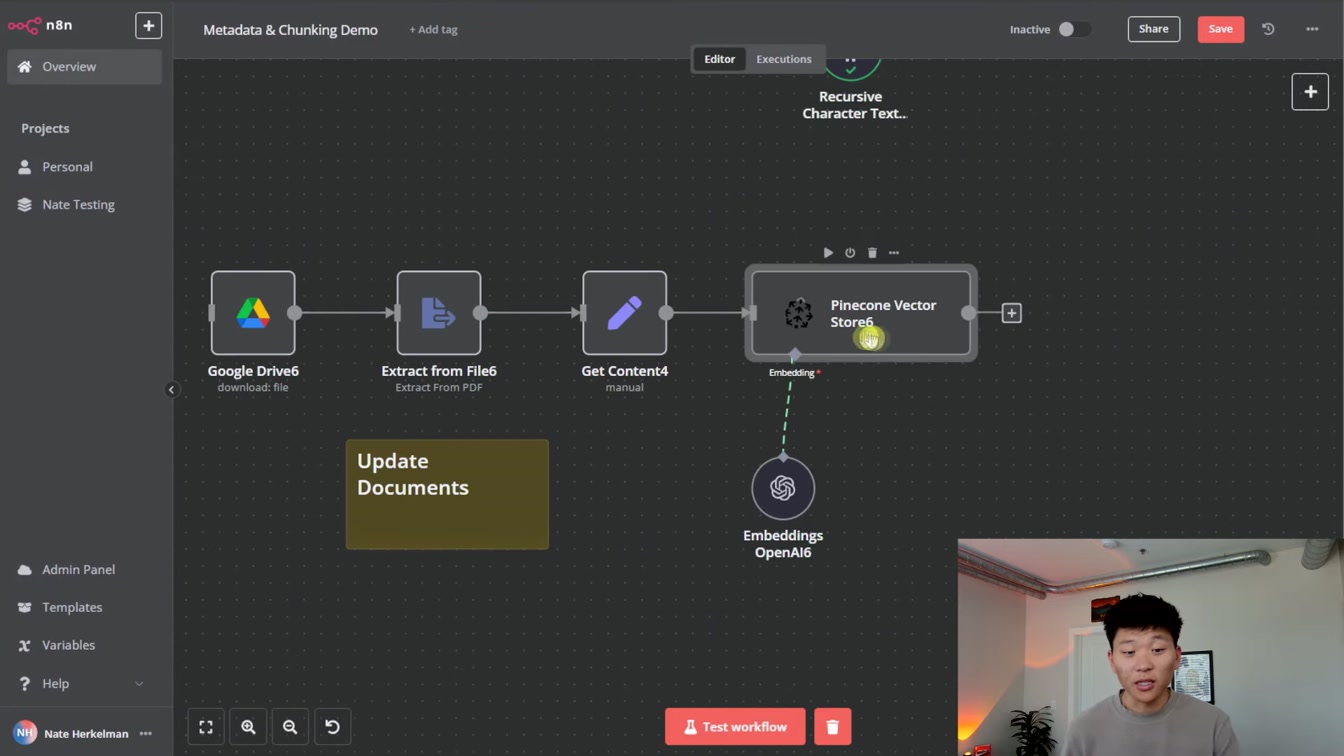
Pinecone 벡터 데이터베이스에서 네임스페이스와 메타데이터 활용법을 쉽게 정리했습니다. 1) 네임스페이스 분할 2) 메타데이터 필터링 3) 문서 순위 지정 방법을 통해 효율적인 데이터 관리 팁을 알려드려요.
관련 링크: 유튜브 바로가기
